

今週のPixAI追加機能はMuiti CotrolNetだ!
今週のってそんな……、まあ確かにここ最近毎週更新してますけど。
Muitiだから複数キャラ対応かスゲーなって思ったら、それは昔からだった。機能的にMulti ControlNetはなんか上級者向けな予感がする
上級者ではないですけど、先々も安心って感じで嬉しいですね!


要約
PixAI.artにMulti ControlNet機能が追加! ということで複数のMethodを組み合わせて遊んでみます。
おもにOpenpose+抽象的な制約をかけるMethodの組み合わせを試して、線で制約するタイプと比較。前者は高い再現性を保ちつつ、制約の少なさからAIが伸び伸びと画像生成して魅力的なキャラクターが描かれる、……ような気がします。
はじめに
3月9日木曜日、PixAI.artで遊ぼうとしたら何かいつもと雰囲気が違う……、よくよく見てみたらControlNetが複数追加できるようになってました。先週はLoRAの追加でしたっけ? ほんと、ここのところ毎週新機能追加してますよね。
複数の棒人形を入力できるようになったのかな? と思ったのですが、それはControlNet一つでもできるみたいです。ということでControlNetのMethodを組み合わせることで、表現の幅が広がった、みたいな感じだと思ってます。
と、なると気になるのがキャラの魅力と再現性のトレードオフ。
ControlNetを使わないでAI画像生成をしてもらうと、魅力的な画像が出てくるけど再現性が低い。ControlNetでCannyとかを使えば再現性は高くなるけど、制約があってのびのび描けないからか、いまいち魅力が下がってしまう。そんな個人的な印象を持っています。
このあたりについてアレコレ遊んでみました。
今回の記事は以下のページの続編的なイメージです。
↓PixAIまとめ

↓ControlNetの基本的な遊び方と「Strength」について

ご一緒に読んでいただけると超嬉しいです!
マルチにコントロール
ひとりでマルチ
まずは基本、ということでOpenPose(棒人形)です。
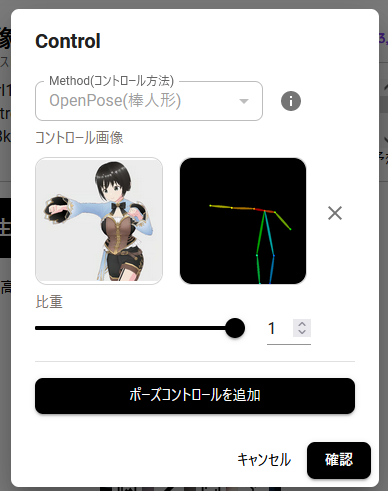

今回のモデルはミノ子魔界バージョン。いつものようにVRoid Studioで作成し、ポーズを取って作成。この状態でもかわいいんですけど、もう一声欲しい。
左側の画像がOpenPoseで棒人形を認識してもらった状態、右側が棒人形を元に「girl1, smile, black short hair, blue dress, Scenes with extreme detail ~」生成してもらった画像です。いつものように前半の単純な説明と、後半の作風プロンプトの組み合わせです。
右側生成画像を見ると、たしかに棒人形のとおりなんですけど、なんかちょっと意図と違うことがわかります。キャラクターの魅力は十分ですね。……手は見ない方向で。
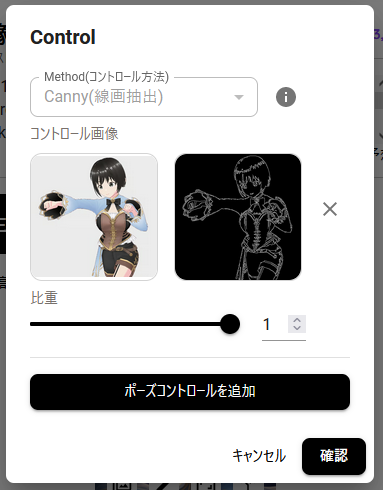

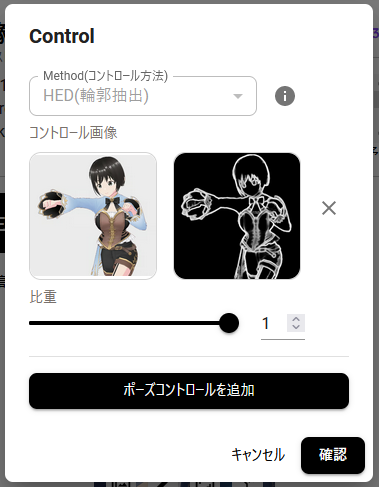

じゃあ再現性を求めたら? ということでCanny(線画抽出)とHED(輪郭抽出)です。ご覧のとおりポーズとしての再現性は高い。……なんですけど、ポーズを取らされてる的な雰囲気を感じるのは気のせいでしょうか? 目に気力がない? ということで魅力がイマイチ。
CannyやHEDのような、直接的に線を指定すると制約が大きいんじゃないかー、と思ってます。でも線を指定しなければ再現性が低い。
と、ここでMulti ControlNetですよ。Openposeとその他の、線を指定しないMethodならどうなるか? 制約が少ないぶん自由に生成してもらえて、魅力的な画像を得られるんじゃね? って発想です。
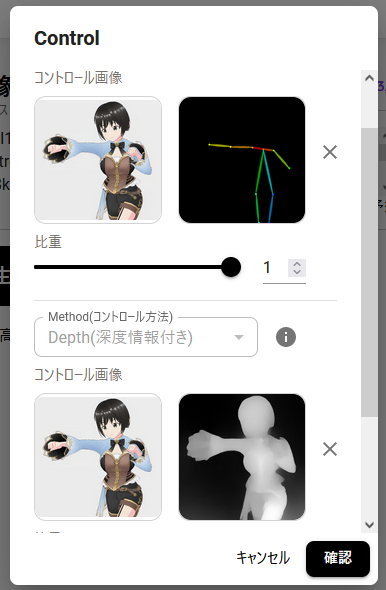


……右側のDepth(深度情報付き)単体で生成した画像が、予想に反して再現性が高かった。どうして震度情報(左側下)だけでここまで再現できるの? おそるべしControlnet。これはちょっと組み合わせた意味ないかも。
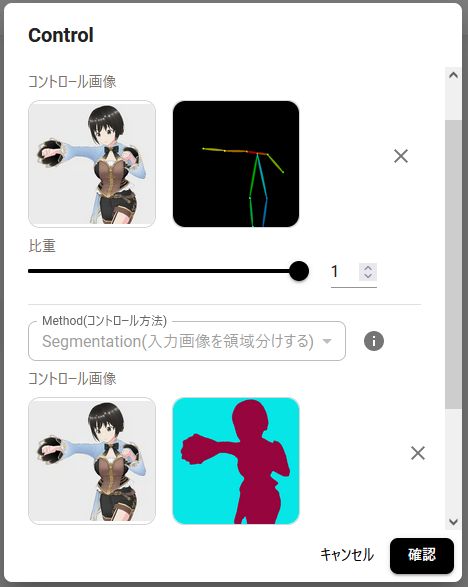


真ん中の画像、OpenPose+Segmentation(入力画像を領域分けする)で生成したものはポーズがきちんと再現されています。キャラクターの魅力もある程度自由に生成しました的な魅力がある(気がする)。
反面Segmentation単体(右側)はポーズが再現されていません。うーん、イイ感じの画像が得られて満足。まさにこれを言いたかったんですよ。
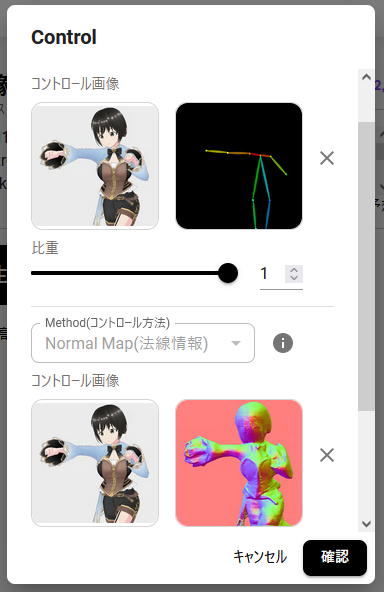


……最後のNormal Map(法線情報)も思ったより単体でしっかり再現された(右側)。このあいだはめちゃくちゃな画像が出てきたのに。ということでこれもまた、あまりの差の出ない検証になってしまいました。
今回は背景無しのポーズ画像を元にしましたけど、背景があったり、キャラクターが何人かいたりする複雑な画像のほうが真価が発揮されるのかも。
みんなでマルチ
ということでお次はみんなでマルチです。みんなって言ってもキャラクターはふたりだけですけど。そもそも今までは、ひとつの棒人形しか生成できないと思っていました。でもそれは気のせいで、ひとつのControlNetでも、しっかりふたり分の棒人形が出てきます。
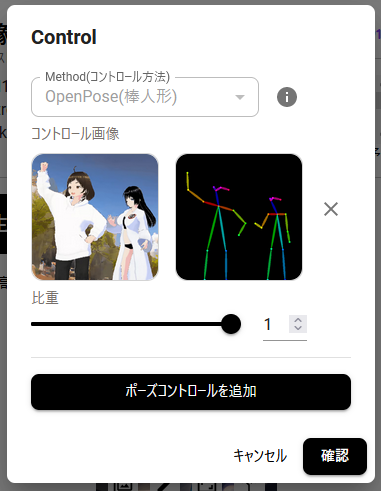
モデル変わってヒロインのはずのシナルです。左の露出狂みたいな人は気にしないでください。ひとつの画像からしっから棒人形がふたり分認識されていることがわかります。よく考えるとこれってすごい技術。なんだか棒人形が漫才やってるみたいですけど。






上の画像を見ていただければ、言いたいことがなんとなくわかっていただけるかと思います。Openposeだけだと自由奔放過ぎる。CannyやHEDのような線で制約するタイプだと、ちょっとキャラクターの魅力が減ってしまう。
そこで抽象的に制約するタイプのMethod(上記の例だとDepth、Segmentation、Normal Map)にOpenposeを組み合わせることで、キャラクターの魅力を損なわず、再現性も担保できるんじゃない? ってことです。
特に一番右下、Openpose+Normal Mapのシナルの再現性に驚いた。ガチャで当たりを引いただけかもだけど、いっつもこんな調子だったら嬉しいです。
まとめ
PixAI.artにMulti ControlNet機能が追加! ということで複数のMethodを組み合わせて遊んでみました。
おもにOpenpose+抽象的な制約をかけるMethodの組み合わせを試して、線で制約するタイプと比較。前者は高い再現性を保ちつつ、制約の少なさからAIが伸び伸びと画像生成して魅力的なキャラクターが描かれる、……ような気がします。
結局は画像ごとの向き不向きとそれを判断する熟練度が必要な上級テクニックなのかもしれませんが、少しでもガチャ的要素を減らせるのであればとてもありがたい。
あとは精進させていただきます!
↓始め方と基本的な遊び方について

↓他のかたのプロンプトを参考にする方法について
↓追加されたMethodを色々試した結果

↓憧れの追加学習LoRAについて

↓棒人形を簡単にセット可能な「ポーズを選ぶ」はこちら


